

目睹这份源自中山大学科研团队的预告,我们终究无需再度坠入恐慌的迷雾里头。依据大数据以及科学模型推导出来的结论为:最近这2到4日之内每日新增确诊将会快速降低,非湖北地区自最开始的防控便是有成效的。这表明我们先前的自我隔离未曾白费。
数学模型如何预判疫情拐点
副教授胡延庆团队所运用的SEIR模型,将疫情传播划分成两个阶段,其一为公众于不知情之际,病毒以基本再生数作为常数的形式进行扩散,其二是全民展开防控之时,再生数持续降低直至小于1,此种划分颇为关键,缘由在于其对防控措施的实际成效予以了量化。
把百度、Google的搜索趋势当作重要参数的是研究团队,数据表明在1月22日左右人们开启大规模对疫情关键词的搜索,而此日恰为武汉封城的前一天,团队把这一时间点往后推一个潜伏期,进而得出在2月1日前后出现拐点的结论,这个推理链条明晰,并非凭空臆测。
线性增长与指数增长的本质区别
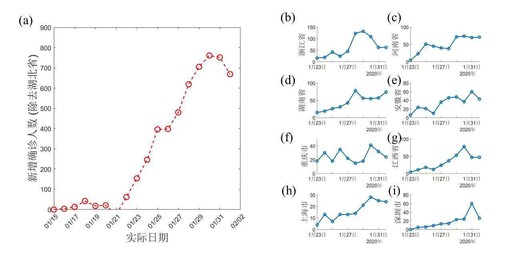
有不少人听闻“新增确诊人数”便心生畏惧,然而却没把曲线形状的含义给弄明白。全国非湖北地区的确诊情况呈现出增长为线性这种态势,并非如同指数爆炸那般。所谓线性,指的是每增加一个感染者,其传染的二代病例数量是固定的,并非成倍地进行放大。
这表明,自武汉流出的那些感染者,抵达全国各地之后,并未于当地引发大规模的传播。各地自1月中旬起所采取的排查、隔离举措是具备成效的。要是呈现出指数增长的态势,那才意味着社区传播处于失控状态。线性增长可是防控有效的数学层面证据。
搜索数据如何预测人群行为变化
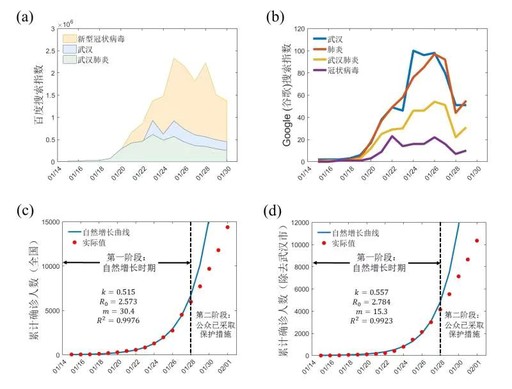
研究团队采用了一个精妙的替代指标,此指标便是搜索指数。当人们着手疯狂搜索“武汉传染病”以及“新型冠状病毒”之际,这表明认知已然达到相应程度。而认知达到相应程度所产生的直接后果乃是戴口罩,并且少出门以及勤洗手。
1月22日前后,搜索量突然间暴增,一周之后,大家基本上都戴上了口罩。研究人员把行为改变的这个时间点,输入了模型里头,预测2月1日左右,病例增速会放缓下来。实际的数据,验证了这个预测结果。在公共卫生应急当中,搜索引擎大数据头一回扮演了这般具体的决策参考角色。
除湖北外累计感染人数的预测价值
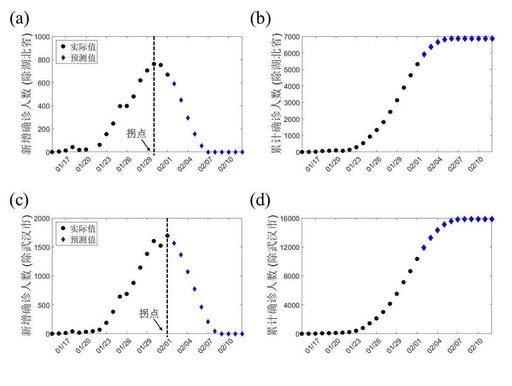
凭借前期传播速率以及防控生效时间进行推算,得出模型预测全国除去湖北省之外累计感染的人数大概接近7000人这一数据,同时还得出除去武汉市之外累计感染人数大概接近16000人这一数据,这两组数字并非随意估摸得来的。
截至二月上旬的实际数据,非湖北地区累计确诊处于六千到七千之间,跟预测高度相符。这表明模型的参数设定是合理的。这组数字也给予了其他省份居民一个相对明晰的预期 ,晓得疫情规模大致有多大 ,不至于被谣言惊吓到。
2月13日复工建议的科学依据
研究团队给出建议,2月13日之后正常上班,此建议乃是从2月1日拐点开始往后推,推一个平均潜伏期,再额外加上几天而得出的。鉴于存在少数病例潜伏期超过14天的情况,以及偏远地区信息存在延迟状况,所以这个时间窗口预留了一定余量。
关于当时全社会最为焦虑的那个问题:究竟何时能够上班,这个建议给出了直接的回应。它并非仅仅是对着日历去拍,而是乃是以源自传播动力学以及实际防控效果的科学判断作为依据。随后各个地方的实际复工节奏确实是大致处在这个时间点的临近位置,是这样的情况。
防控有效不等于可以放松警惕
论文结尾着重指出,病例数量降低的主要缘由是人群自身的保护行为,并非病毒变弱了。一旦大家重新恢复聚集,且不佩戴口罩,传播指数随时都有可能出现反弹。这个警示在数据呈现向好态势的时候格外重要。
模型所进行预测的,乃是处于维持当下防控水平这个前提条件之下的走势情况。要是认为拐点一旦出现便一切都没问题了,那么反倒有可能致使第二个高峰的出现。科学预测所具备的价值,在于告知我们什么是做对了的事情,并且给出建议让我们持续如此做下去。
当时,你是否留存过疫情刚开始那段时期自己每日去刷数据所得到的截图,或者留存过相关日记呢?那个时候,究竟是哪些信息致使你下定决心开始佩戴口罩,并且取消聚会的呢?欢迎于评论区去分享你个人的防控时间线,以此让更多的人得以看到作为普通人在疫情里面所展现出的科学判断力。要是觉得这篇文章具备用处,那就请点赞并转发,从而能够让更多的人去了解大数据预测背后所蕴含的道理。



